인프라 · 배포
대표 글상용 서버가 2.5일마다 죽었다 - 빠른 배포가 3주 동안 숨겨온 메모리 누수
상용 web 서버가 원인 불명 OOM으로 두 번 전면 장애를 냈다. 관측 도구가 없어 원인을 볼 수 없으니, 대응은 매번 메모리를 늘려 버티는 것뿐이었다. 첫 사고(3주 전) 때 백엔드 동료가 SSE 연결 누수 가설을 슬랙에 남겼지만, 그땐 원인을 볼 수 있게 만드는 게 먼저라 팀은 dd-trace 설치에 집중했고 그 메모는 잠시 묻혔다. 두 번째 사망 다음 날, 하루를 통째로 들여 끝까지 파고들었다. 누수를 잡아낸 건 그때 깔아둔 dd-trace였다.
새벽 알림의 실체 - 알림 시각 ≠ 사고 시각
시작은 새벽 00:29의 Datadog RUM 알림("frontend error rate > 5%")이었다. 처음엔 이게 OOM의 신호인 줄 알았다. 아니었다.
- 00:29 알림의 실체 - RUM Explorer로 까보니 React #418 하이드레이션 에러. 사고와 무관한 노이즈였다 (하이드레이션 완료 전 메뉴 클릭 경합 - 3주 묵은 별개 이슈)
- 진짜 사고는 45분 뒤 - 파드 이벤트 실측:
01:13~01:17readiness probe 응답 불가 ×25(메모리 포화로 빈사) →01:18컨테이너 사망 →01:24메모리 2배 증설 파드로 수동 교체 - 그리고 그 진짜 사고 구간엔 알림이 한 건도 없었다
첫 번째 발견이 이것이었다. 알림을 따라가면 엉뚱한 곳에 도착한다 - 알림의 실체를 먼저 판별해야 했다.
관측 도구 다섯으로 사건을 좁히다
단서가 흩어져 있어서, 관측 도구를 하나씩 훑으며 "무엇을 배제하고 무엇을 남길지"를 좁혔다.
| 창 | 본 것 | 결론 |
|---|---|---|
| 배포 설정 리포 커밋 | 01:24 메모리 증설 커밋 | "메모리 사망 + 수동 대응" 정황 |
| kubectl | 새 파드 시작 01:24:20, replicas 1 | 커밋과 일치 · 단일 파드(SPOF) 확인 |
| RUM Explorer | 00:29 알림 = 하이드레이션 노이즈 | 사고와 분리 (배제) |
| APM (dd-trace) | 사고 시간대 서버 에러 0 | "5xx를 뱉고 죽은 게 아니다" (배제) |
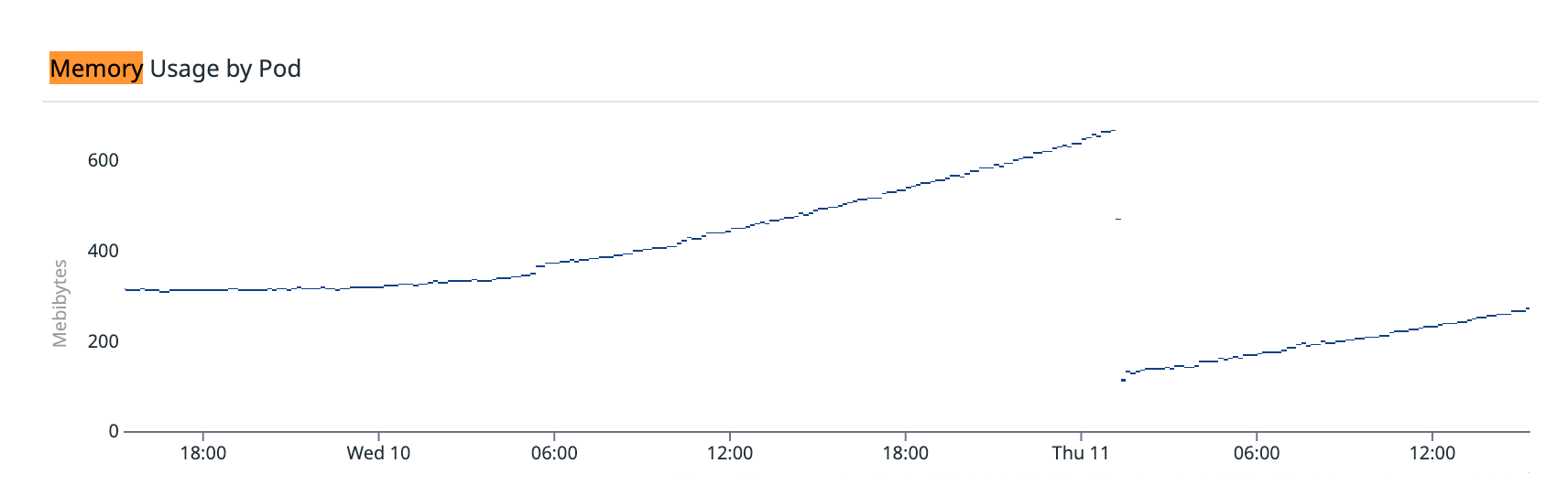
| 메모리 그래프 | 기울기 ~12Mi/h 우상향 → 사망 → 새 파드도 같은 기울기로 재상승 | 누수 확정 방향 |
| 파드 이벤트 | readiness 실패 ×25 | 평균 그래프가 숨긴 마지막 5분 보완 |
여기서 산수가 맞아떨어졌다. 12Mi/h × 60시간 ≈ 0.9Gi - 직전 배포 파드가 정확히 2.5일 만에 1Gi 한계에 닿아 죽은 주기와 일치했다. 우연이 아니라 일정한 속도의 누수였다.
원인 - 프록시가 "떠남"을 전달하지 않았다
용의자는 SSE 프록시 라우트(이메일 이벤트·채팅 unread 구독 중계)였다.
[브라우저] ←연결①→ [Next 서버(web 파드)] ←연결②→ [백엔드]프록시의 upstream fetch에 signal: req.signal이 빠져 있었다. 그 결과 연결①(브라우저)이
끊겨도 연결②(백엔드)는 살아남았다. 탭을 닫고 떠난 사용자마다 좀비 연결이 하나씩 남아 백엔드가
보내는 chunk를 계속 수신·적재했다. maxDuration = 300이 있었지만 self-hosted에선 보장되지
않는다 - 실측으로 좀비가 34분 넘게 살아 있었다. 사용자 출입이 반복되는 하루 동안 좀비가
누적되며 메모리가 일정한 기울기로 차올랐던 것이다.
왜 3주 동안은 멀쩡했나 - 빠른 배포가 가린 누수
누수가 12Mi/h면 2.5일이면 한계에 닿는다. 그런데 첫 사고 뒤 3주 동안은 왜 안 터졌을까. 답은 배포 주기에 있었다.
애자일 프로세스가 들어오며 하루 한 번 이상 상용 배포가 나가던 시기엔, 파드가 2.5일을 채우기 전에 매번 새로 떠서 메모리가 리셋됐다 - 누수는 그대로 있었지만 죽을 시간이 없었다. 그러다 API 대규모 리팩토링이 들어가며 상용 배포를 잠시 멈추자, 파드가 처음으로 2.5일을 넘겨 살았고, 묻혀 있던 누수가 그제서야 한계에 닿았다.
빠른 배포가 증상을 가리고 있었던 것이다. "갑자기 생긴 문제"가 아니라 "원래 있었는데 드러난 문제" 였고 - 첫 사고 때 슬랙에 남았던 SSE 메모가 결국 맞는 방향이었다. 묻어둔 가설을 다시 꺼낼 시간이었다.
"아닐 수도 있다"를 로그 두 줄로 끝내다
가설은 3주 전부터 있었다. 부족했던 건 증거였다. 그래서 실제 라우트와 동일 구조의 프로브 두 개(가짜 백엔드 + 프록시)를 만들어 A/B로 재현했다.
// probe-proxy - 실제 SSE 라우트와 동일 구조 (?signal=off = 픽스 전 상태)
const useSignal = req.nextUrl.searchParams.get("signal") !== "off";
const response = await fetch("http://localhost:3005/api/probe-upstream", {
headers: { Accept: "text/event-stream" },
...(useSignal ? { signal: req.signal } : {}),
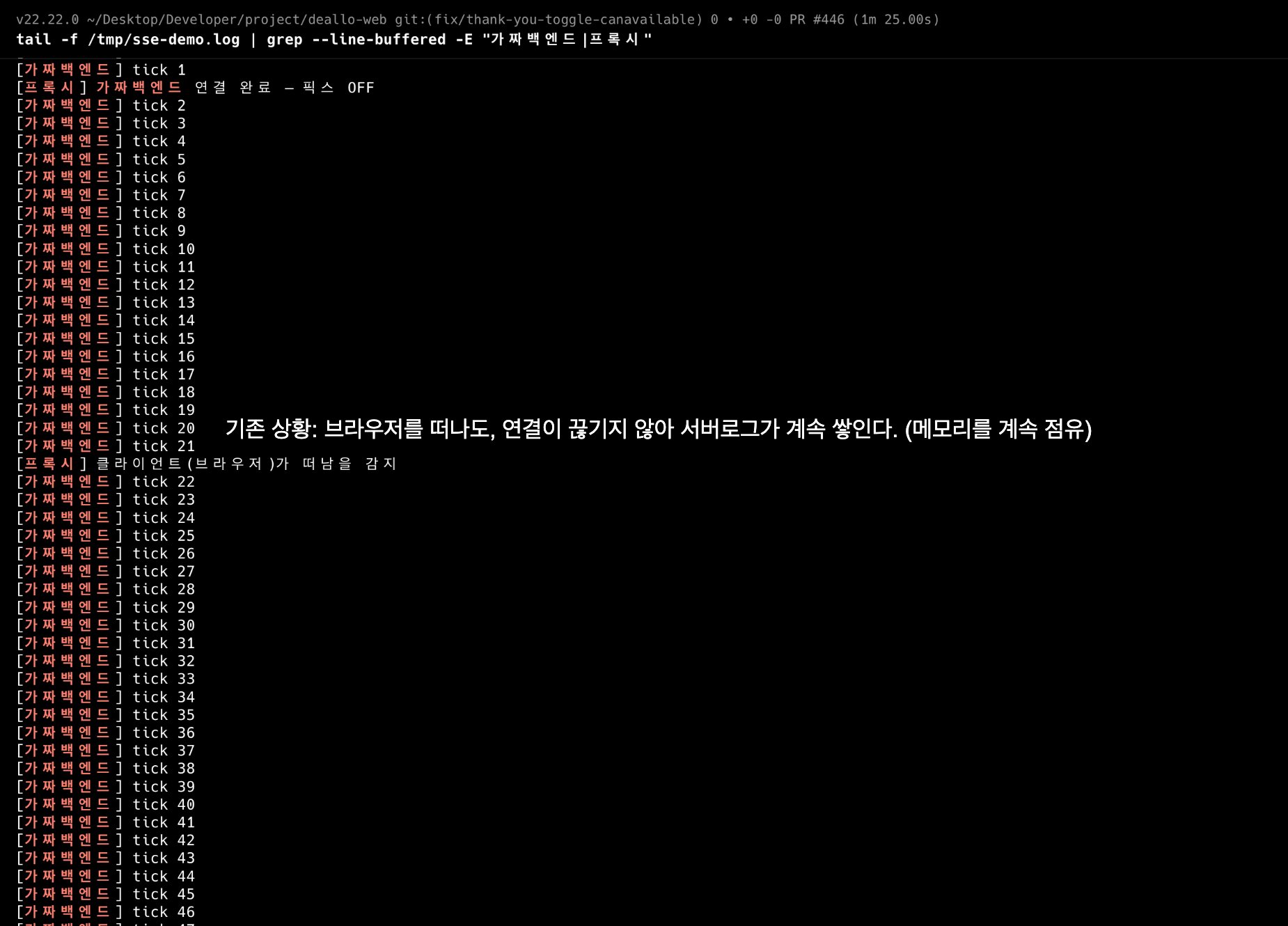
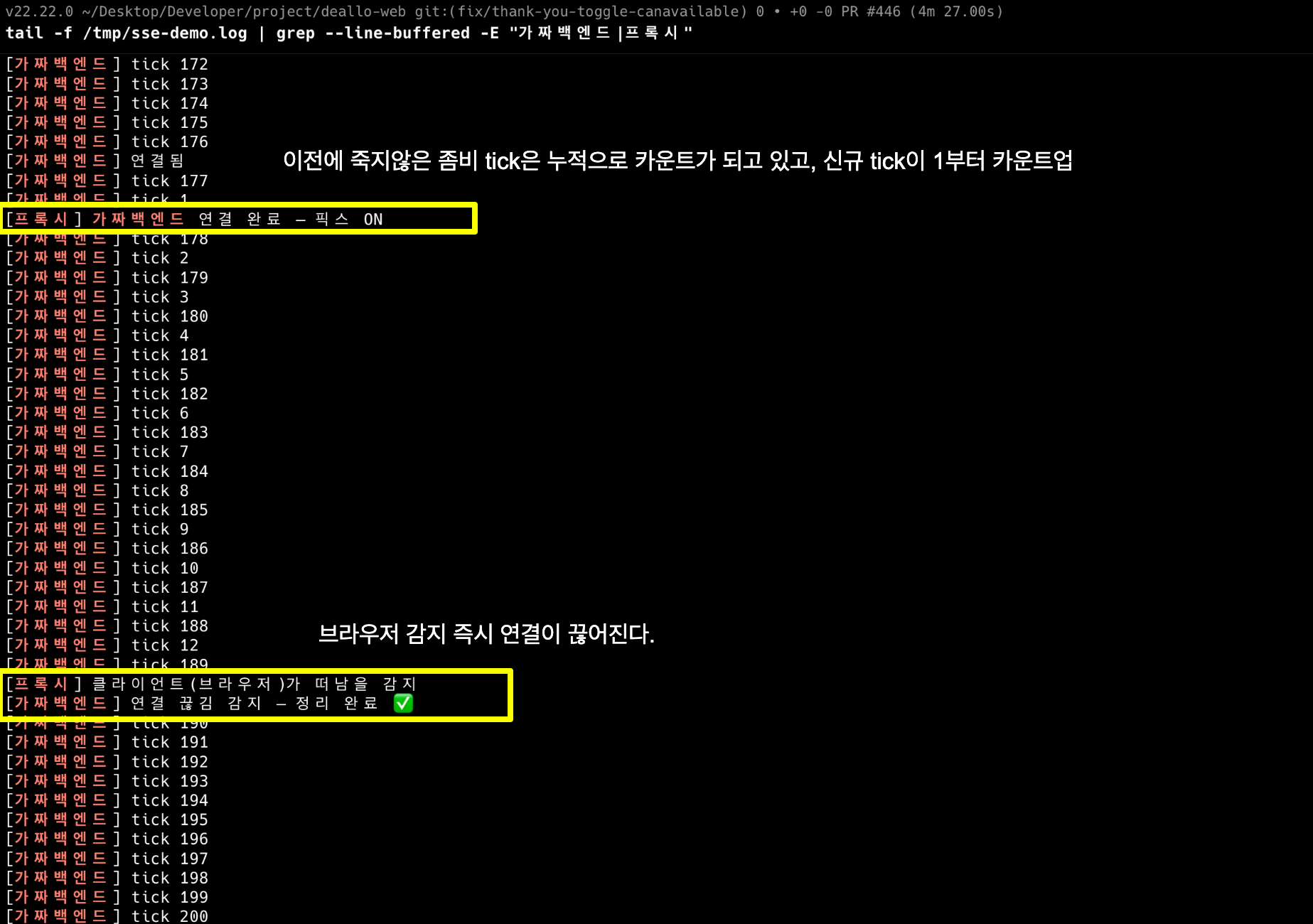
});가짜 백엔드는 1초마다 tick을 보내고, 연결이 끊기면 "정리 완료 ✅"를 찍는다. 클라이언트를 4초 보다가 강제 종료(탭 닫기와 동일)한 뒤 로그를 관찰했다.
픽스 전(signal=off): [프록시] 클라이언트가 떠남을 감지 … 그런데 tick은 계속 (34분+ 생존)
픽스 후 : [프록시] 클라이언트가 떠남을 감지 → [가짜백엔드] 정리 완료 ✅ → tick 정지"아닐 수도 있다"던 가설이 로그 두 줄로 끝났다. 재현이 곧 설득이었다 - 이 시점부터 누구도 원인을 의심하지 않았다.
픽스는 사실상 한 줄
const response = await fetch(url.toString(), {
method: "GET",
headers,
signal: req.signal, // 클라이언트가 끊으면 백엔드 연결도 함께 종료
});
// catch: 연결 수립 중 클라이언트 이탈(AbortError)은 502가 아닌 204로 -
// 정상 취소를 실패로 오분류하지 않기- 백엔드 변경 불요 - 끊김을 "당하는" 쪽은 IOException/onCompletion으로 자체 정리되는 표준 동작
- 과거 Next 버전에서
req.signal이 발화하지 않던 이력이 있어, 현재 버전에서 정상 동작함을 재현으로 먼저 검증하고 적용했다 - 일반 REST는 "클라이언트가 취소해도 서버는 끝까지 처리"가 맞다. SSE가 다른 건 끝이 없는 연결이라서다
픽스 전후의 로그를 나란히 두면 이렇다.
릴리스 전 일주일 - 예방적 재시작으로 버티기
픽스는 머지됐지만 상용 릴리스는 다른 작업에 묶여 다음 주로 밀렸다. 그 사이 누수는 멈추지 않는다 - 재시작된 파드가 하루 만에 한계의 35%까지 다시 차올랐다. 같은 기울기로 다시 새는 것 자체가 "환경이 아니라 코드"라는 추가 증거였고, 동시에 주말을 그냥 넘기면 세 번째 사망이 예약돼 있다는 뜻이기도 했다.
그래서 임시 조치를 택했다 - ArgoCD에서 무중단 재시작, 792Mi → 70Mi 리셋. 재시작이 근본 해결이 아니라는 건 이 글에서 내내 말한 그대로다. 하지만 픽스 배포가 일정에 묶여 있는 동안엔 시간을 버는 것도 의도된 운영이다. 이전 두 번과 다른 점은 하나 - 이번엔 "왜 차오르는지" 알고 누른 재시작이라는 것.
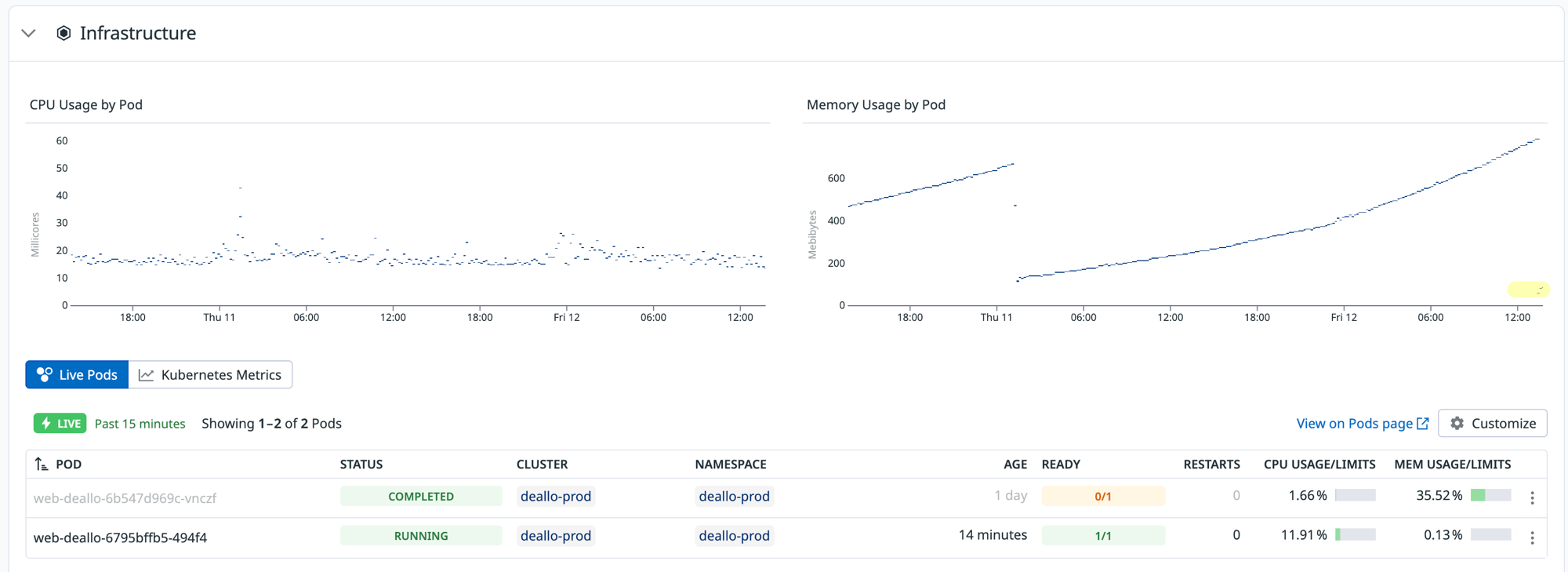
이 그래프엔 절벽이 두 번 나온다. 첫 번째는 사망, 두 번째는 예방. 픽스를 릴리스하면 세 번째는 없어야 한다 - 더 차오르지 않는 평평한 선.
릴리스 후 - 평평해진 메모리
며칠 뒤 픽스를 상용에 배포했다. 우상향하던 선이 배포 시점에 바닥으로 떨어진 뒤로 다시 차오르지 않았다. 사용자가 드나들어도 좀비 연결이 안 남으니, 메모리가 더 쌓일 데가 없다.
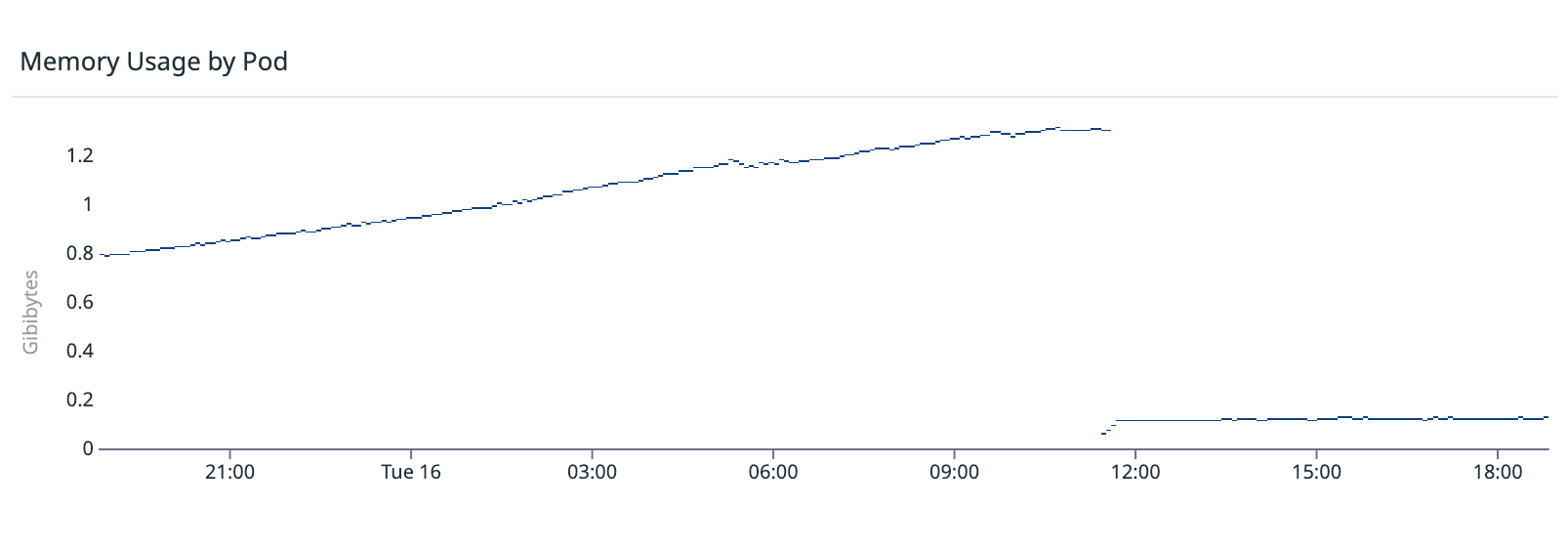
2.5일마다 1Gi 한계까지 차오르던 선이, 좀비 연결을 끊은 뒤로는 평평하다. 그 뒤로 web 서버는 메모리 때문에 죽지 않았다.
부산물 - 사건이 드러낸 모니터링의 구멍
원인을 쫓는 동안 모니터링 체계의 결함이 줄줄이 드러나, 사건과 함께 수리했다.
- OOMKilled 모니터가 정작 OOM을 못 잡고 있었다 - 쿼리가
reason:error인데 실제 태그값은oom. 게다가 "데이터 없으면 마지막 상태 유지" 설정 탓에 옛 Alert가 그대로 남아 있었다 → 쿼리·설정 수정 - 진짜 사고 구간 알림 0건 - 위 수리로 다음 사고부턴 즉시 알림
- RUM 에러율 모니터의 저트래픽 함정 - 페이지별 비율이라 새벽 1세션의 에러로도 발화 → 최소 트래픽 가드 검토
- 에러 필터의 철자 갭(
CanceledError만 필터, double-LCancelledError통과), web 단일 replica(SPOF) 증설 제안 등
남긴 것
- 알림 시각 ≠ 사고 시각. 알림의 실체를 판별하지 않으면 45분 떨어진 엉뚱한 곳을 판다
- 평균 그래프는 마지막 급등을 숨긴다 - 파드 이벤트(readiness 실패)가 그 마지막 5분을 보완했다
- 메모리 증설·재시작은 근본 해결이 아니다. 누수 자체를 막기 전엔 반복된다 - 증설 2회가 그 증거다. 릴리스 전의 예방 재시작도 그래서 "임시"임을 전제로 진행했다
- 가설은 재현으로 확정한다. 3주를 버틴 "아닐 수도 있다"가 A/B 프로브 앞에서 하루 만에 끝났다
- 빠른 배포가 버그를 가릴 수 있다. 잦은 재시작이 누수를 매번 리셋해 사망을 막고 있었다 - 배포가 멈추자 드러났다. "최근에 잘 돌던 코드"가 멀쩡하다는 뜻은 아니다
- 관측을 먼저 깐 게 결국 사건을 풀었다. 첫 사고 때 원인보다 dd-trace 설치를 앞세운 판단이 당장은 답을 미룬 것 같았지만, 3주 뒤 그 도구가 누수 그래프를 보여줬다. 못 보는 문제는 못 고친다
- Next BFF 시대의 FE는 "프론트 레포 안의 서버"를 같이 책임진다 - 이 누수는 프론트 레포의 서버 코드였고, 추적 도구는 kubectl과 APM이었다. FE의 경계는 브라우저에서 끝나지 않는다