실시간 · 스트리밍
스트리밍 응답의 무한 로딩 - status 이벤트가 여러 개 올 때
챗봇을 가짜 스트리밍에서 진짜 스트리밍으로 바꾸자, 특정 질문에서 응답이 끝났는데도 로딩
인디케이터가 사라지지 않는 버그가 나타났다. 원인은 스트리밍 프로토콜의 status 이벤트가 한
번만 온다는 전제에 있었다. 모델이 status를 2~3개 보내는 순간 그 전제가 깨졌고, 나는 "메시지를
개수로 쌓지 말고 항상 하나로 보장한다"로 이 전제를 다시 세워 풀었다.
배경 - 가짜 스트리밍에서 진짜 스트리밍으로
처음 챗봇은 LLM 응답 전체를 한 번에 받은 뒤, 프론트에서 한 글자씩 찍어 실시간처럼 보이게 했다. 겉보기엔 타이핑 효과였지만, 실제로는 응답이 다 도착한 다음에야 출력이 시작돼 "다 받을 때까지의 시간"이 그대로 첫 글자까지의 지연으로 쌓였다.
// 가짜 스트리밍 (기존) - 전체를 받은 뒤 한 글자씩 setTimeout
const streamText = (fullText: string) => {
const chars = fullText.split('');
let i = 0;
const streamNext = () => {
if (i >= chars.length) return; // 끝
setChats((prev) => /* 마지막 메시지에 chars[0..i] 반영 */ prev);
i++;
setTimeout(streamNext, 50);
};
streamNext();
};그래서 응답을 받는 방식 자체를 바꿨다. 다른 프로젝트의 스트리밍 구현을 참고해 팀원과 함께
전환에 착수했다 - axios로는 스트리밍을 받을 수 없어 fetch로 바꾸고, response.body의
ReadableStream을 getReader()로 읽어 도착하는 청크부터 화면에 흘리는 구조로 옮겼다. 서버는 한 응답 스트림 안에서 event가
status → token → result로 바뀌는 JSON 청크들을 개행으로 이어 보낸다.
// 진짜 스트리밍 - 청크를 도착하는 대로 읽는다
const reader = response.body?.getReader();
while (!isDoneRef.current) {
const { done, value } = await reader.read();
if (done) break;
const chunk = new TextDecoder().decode(value); // Uint8Array → 문자열
chunk.split('\n').forEach((line) => {
if (!line) return;
const { event, data } = JSON.parse(line); // event: 'status' | 'token' | 'result'
// status → 진행 메시지 / token → 본문 누적 / result → 최종 확정
});
}event별 역할은 이렇게 나뉜다 - status는 "질문을 분석중입니다" 같은 진행 안내, token은
생성되는 본문 청크(뒤에 ● 인디케이터를 붙여 표시), result는 완성된 전문으로 마지막
메시지를 확정한다. 그렇게 스트리밍으로 전환하고 나니, 이 프로토콜 위에서 새 버그가 따라 나왔다.
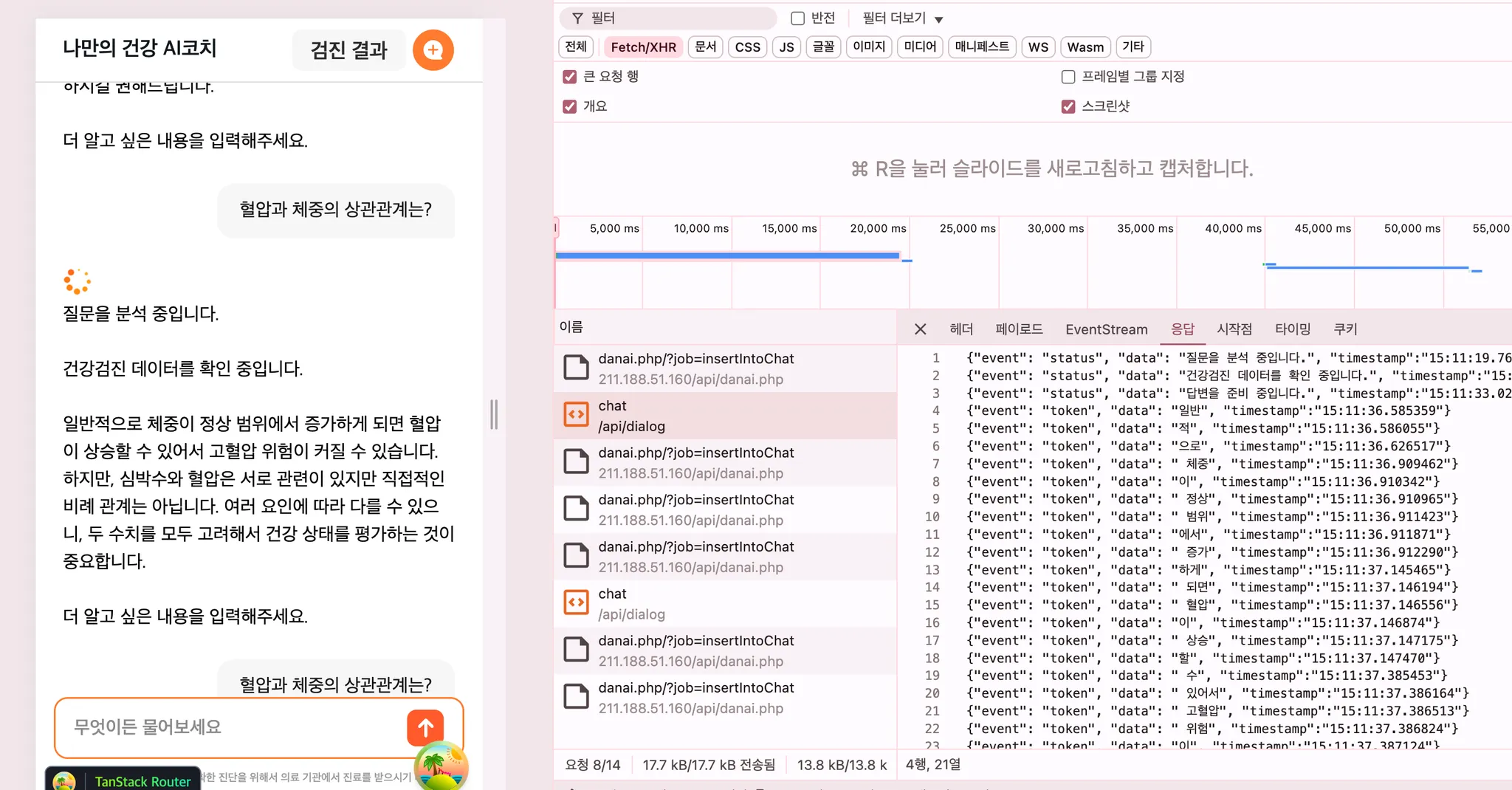
status·token 이벤트).문제 - status가 3개 오자 로딩이 멈추지 않았다
전환 직후, 특정 질문에서 모델 응답의 event:status가 3개 도착하면 응답이 끝나도 로딩 아이콘이
사라지지 않았다. 재현은 됐지만 원인은 코드가 아니라 코드가 기댄 전제에 있었다.
기존 status 핸들러는 이벤트가 하나만 온다고 전제하고, 올 때마다 id: 'streaming' 메시지를
배열에 새로 추가했다.
// 기존 - status마다 'streaming' 메시지를 새로 push
.with({ event: 'status' }, ({ data }) => {
setChats((prev) => [
...prev,
{ id: 'streaming', messageText: data, senderType: SenderType.chatbot },
]);
})로딩 종료 판정은 "id: 'streaming'인 메시지가 남아 있는가"로 하는데, status가 여러 개면
streaming 메시지도 여러 개 쌓인다. 마지막을 result가 덮어써도 앞에 쌓인 streaming들이
그대로 남아 로딩이 끝나지 않았다.
1. 첫 status → id:'streaming' 메시지 생성
2. 둘째 status → 새 id:'streaming' 메시지 추가 (기존 유지)
3. 셋째 status → 또 id:'streaming' 메시지 추가
4. result → 마지막 메시지 하나만 대체
5. 결과: 남아 있는 id:'streaming' 메시지 때문에 무한 로딩해결 - 개수로 쌓지 말고, 항상 하나로 보장한다
고칠 지점은 명확했다. status가 몇 개 오든 streaming 메시지는 항상 하나만 존재하게 만들면
된다. 그래서 status가 올 때 무조건 추가하지 않고, 마지막 메시지가 이미 streaming이면
덮어쓰고, 아니면 그때만 새로 추가하도록 바꿨다.
// 변경 - 마지막이 'streaming'이면 덮어쓰고, 아니면 새로 추가
.with({ event: 'status' }, ({ data }) => {
setChats((prev) => {
const lastMessage = prev[prev.length - 1];
if (lastMessage?.id === 'streaming') {
return [...prev.slice(0, -1), { ...lastMessage, messageText: data }];
}
return [
...prev,
{ id: 'streaming', messageText: data, senderType: SenderType.chatbot },
];
});
})1. 첫 status → id:'streaming' 생성
2. 둘째 status → 마지막이 'streaming' → 덮어쓰기 (개수 그대로 1)
3. 셋째 status → 덮어쓰기 (여전히 1)
4. result → 그 하나를 최종 메시지로 확정
5. 결과: 'streaming' 메시지가 남지 않아 로딩 정상 종료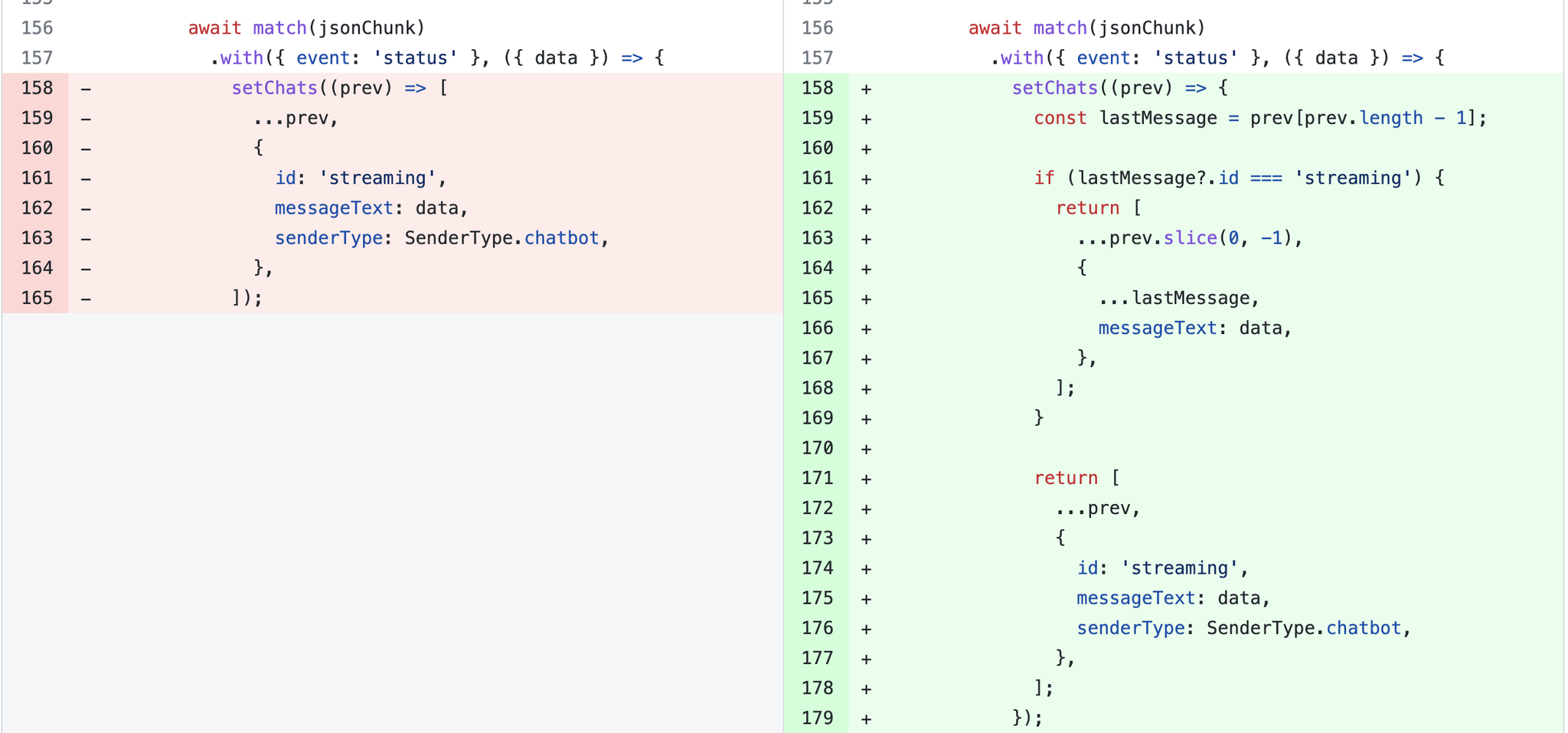
streaming이면 새로 추가하지 않고 덮어쓰도록 수정.token은 손댈 필요가 없었다 - 이미 streaming 메시지가 하나로 보장되므로, 마지막 메시지 하나만
누적 업데이트하면 됐다. "이벤트가 한 번만 온다"는 암묵적 전제를, "메시지는 항상 하나"라는 명시적
불변식으로 바꾼 것이 이 수정의 전부다.
스트리밍이라 따로 챙긴 것들
일반 요청은 "받았다/실패했다"가 끝이지만, 스트리밍은 받는 도중에 무슨 일이든 생길 수 있다. 그래서 정상 흐름보다 중간 상태를 먼저 그렸다.
- 응답 지연 - 첫 청크가 오기 전까지 로딩 인디케이터로 "진행 중"을 명시해 빈 화면을 만들지 않는다
- 중간 끊김 - 도중에 끊겨도 이미 받은 텍스트는 버리지 않고 화면에 남긴다.
streaming메시지를 하나로 보장한 위 구조 덕에, 끊겨도 마지막 상태가 그대로 보존된다 - 멀티바이트 경계 -
TextDecoder로Uint8Array청크를 문자열로 디코딩할 때, 한글은 청크 경계에서 잘릴 수 있다. 바이트 경계와 문자 경계가 다르다는 걸 전제하고 디코딩을 다뤄야 했다
이 프로젝트에서 나는 스트리밍 종료 시점의 UX도 함께 맡아, LLM 응답이 끝날 때만 주의 문구가 붙도록 누적 텍스트 처리를 손봤다(응답별로 문구가 중복되던 것을 종료 시 한 번으로).
결과
status가 여러 개 와도 로딩이 정상 종료- 끊김·지연에도 받은 내용은 보존되어 대화가 끊겨 보이지 않음
- 진짜 스트리밍 전환으로 첫 텍스트가 보이기까지의 체감 지연이 크게 줄었다
배운 점
- 버그는 코드가 아니라 코드가 기댄 전제에 있었다. "
status는 한 번만 온다"는 암묵적 전제가 깨지자 무한 로딩이 터졌다. 고친 건 핸들러 몇 줄이지만, 실제로 바꾼 건 그 전제였다. - 상태는 개수로 세지 말고 불변식으로 보장한다.
streaming메시지를 "올 때마다 추가"에서 "항상 하나"로 바꾸니, 이벤트가 2개든 3개든 로딩 종료 판정이 일관됐다. 세는 대신 보장하는 쪽이 견고했다. - 스트리밍은 정상 흐름보다 중간 상태를 먼저 설계해야 한다. 지연·중간 끊김·멀티바이트 경계처럼, "한 번에 다 받는다"가 깨진 모델에서만 나오는 예외들을 먼저 그려야 대화가 끊겨 보이지 않았다.
- 구조를 안다고 버그가 보이는 건 아니었다.
status/token/result스트리밍 프로토콜을 한 단계씩 되짚어 로딩 판정이 어디서 걸리는지 짚고서야, 최소 수정 지점이 보였다.